小样本学习-加速垂直场景下AI普惠化
深度学习确实对人工智能起到了巨大的推动作用,但同时,其也存在着天生的缺陷。一直以来,人工智能都依赖大量的数据进行模型训练,但这带来了过度收集个人数据、数据标注工作量大,数据领域存在“数据孤岛”等问题。 深度学习是基于大数据,通过多层网络实现对“抽象概念”的理解,数据越多其效果相应就越好。而对于人类来说,推理是一项天生技能,只需要从少量数据样本中学习,利用特征+推理的方法往往就可以进行有效的判别,这就是人类举一反三的能力,即便没有过去的知识积累,专业知识欠缺,也有 “照猫画虎”的可能性。从这个角度来说,以深度学习为核心的人工智能还远远不及人类,人类面对陌生环境依然能够通过学习做出适应变化。因此,“类人智能
学习”首先要解决深度学习的这种弊端,即不依赖大数据也能进行自我学习。
目前,基于小数据算法应用于长尾的应用场景已是国内平台公司和创新型公司不断深入的新兴领域。比如:在城市治理方面,商汤在共享单车违停、乱丢垃圾检测以及遛狗合规性洞察等小众、长尾需求等方面的尝试;早在 2020 年,商汤已开始聚焦长尾应用,在世界人工智能大会上商汤用了很大篇幅介绍其 AI 长尾应用。另一家典型的小数据算法公司创新奇智,近几年在智能制造、AI 质检等制造业领域,实现了 AI 场景化落地的突飞猛进。
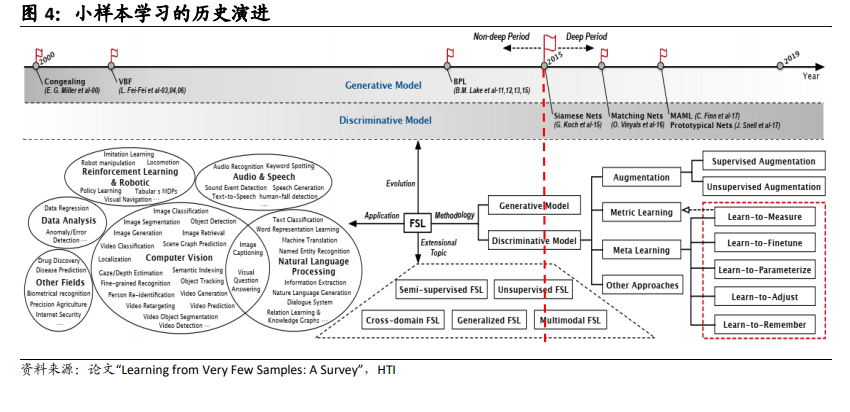
随着深度学习的蓬勃发展,特别是 CNN(卷积神经网络)在视觉任务上取得的巨大成功,许多 FSL 研究者开始将目光从非深度模型转向深度模型。2015 年,G.Koch 等人率先将深度学习纳入 FSL 问题的解决方案中,提出了基于孪生卷积网络CNN(Siamese CNN),对成对的样例进行无相关类别的相似性度量学习(Metriclearning),这标志着 FSL 新时代的开始,即深度阶段。之后,FSL 方法充分利用了深度神经网络在特征表示和端到端模型优化方面的优势,从各个不同角度解决 FSL问题,包括数据增强、度量学习和元学习等,将 FSL 研究推向快速发展的新时期。在深度阶段尽管也提出过一些基于生成模型的方法,比如神经统计学和顺序生成模型,但基于分类模型的 FSL 方法主导了 FSL 研究的发展。近年来,涌现了大量基于元学习的 FSL 方法,如 O.Vinyals 等人的匹配网络、C.Finn 等人的 MAML、S.Ravi 和H.Larochelle 的元学习 LSTM、a.Santoro 等人的 MANN、T.Munkhdalai 和 H.Yu 的MetaNet、J.Snell 等人的原型网、F.Song 和 H.Li 等人的 LGM Nets 等等,元学习策略已成为 FSL 的主流。在这个时期,各种先进的 FSL 方法已被直接应用或改进,以解决计算机视觉、自然语言处理、音频和语音、数据分析、机器人等领域的各种应用,而广义 FSL 和多模态 FSL 也已经出现。